Fundamentals of Machine Learning
1. Intro to Machine Learning
Alex Avdiushenko
October 8, 2024
What is ML?

ML is built using the tools of mathematical statistics, numerical methods, mathematical analysis, optimization methods, probability theory, and various techniques for working with data in digital form.
What is it?
\[\begin{cases} \frac{\partial \rho}{\partial t} + \frac{\partial(\rho u_{i})}{\partial x_{i}} = 0 \\ \\ \frac{\partial (\rho u_{i})}{\partial t} + \frac{\partial[\rho u_{i}u_{j}]}{\partial x_{j}} = -\frac{\partial p}{\partial x_{i}} + \frac{\partial \tau_{ij}}{\partial x_{j}} + \rho f_{i} \end{cases} \]In machine learning, there is no pre-set model with equations...
Types of Machine Learning
- Supervised Learning: The algorithm is provided with labeled training data, and the goal is to learn a general rule that maps inputs to outputs
- Unsupervised Learning: The algorithm is provided with unlabeled data and must find the underlying structure in the data, like clustering or dimensionality reduction
- Reinforcement Learning: The algorithm learns by interacting with an environment and receiving feedback in the form of rewards or penalties
Main notations
$X$ — set of objects
$Y$ — set of answers
$y: X \to Y$ — unknown dependence (target function)
The task is to find, based on the training sample $\{x_1,\dots,x_\ell\} = X_\ell \subset X$
with known answers $y_i=y(x_i)$,
an algorithm ${\color{orange}a}: X \to Y$,
which is a decision function that approximates $y$ over the entire set $X$
The whole ML course is about this:
- how objects $x_i$ are defined and what answers $y_i$ can be
- in what sense ${\color{orange}a}$ approximates $y$
- how to construct the function ${\color{orange}a}$
$f_j: X \to D_j$
The vector $(f_1(x), \dots, f_n(x))$ is so called "feature description" of the object $x$
Types of features:
- $D_j = \{0, 1\}$ — binary
- $\#|D_j| < \infty $ — categorical
- $\#|D_j| < \infty, D_j$ ordered — ordinal
- $D_j = \mathbb{R}$ — real (quantitative)
Data matrix (objects and features as rows and columns):
$F = ||f_j(x_i)||_{\ell\times n} = \left[ {\begin{array}{ccc}
f_1(x_1) & \dots & f_n(x_1) \\
\vdots & \ddots & \vdots \\
f_1(x_\ell) & \dots & f_n(x_\ell)
\end{array} } \right]$
Types of tasks
Classification
- $Y = \{-1, +1\}$ — binary classification
- $Y = \{1, \dots, M\}$ — multiclass classification
- $Y = \{0, 1\}^M$ — multiclass with overlapping classes
Regression
$Y = \mathbb{R}\ $ or $\ Y = \mathbb{R}^m$
Ranking
$Y$ — finite ordered setPredictive Model
A model (predictive model) — a parametric family of functions
$A = \{g(x, \theta) | \theta \in \Theta\}$,
where $g: X \times \Theta \to Y$ — a fixed function, $\Theta$ — a set of allowable values of parameter $\theta$
Example
Linear model with vector of parameters $\theta = (\theta_1, \dots, \theta_n), \Theta = \mathbb{R}^n$:
$g(x, \theta) = \sum\limits_{j=1}^n \theta_jf_j(x)$ — for regression and ranking, $Y = \mathbb{R}$
$g(x, \theta) = \mathrm{sign}\left(\sum\limits_{j=1}^n \theta_jf_j(x)\right)$ — for classification, $Y = \{-1, +1\}$
Example: Regression Task, Synthetic Data
$X = Y = \mathbb{R}$, $\ell = 50$ objects
$n = 3$ features: $\{1, x, x^2\}$ or $\{1, x, \sin x\}$
Training Stage
The method $\mu$ constructs an algorithm $a = \mu(X_\ell, Y_\ell)$ from the sample $(X_\ell, Y_\ell) = (x_i, y_i)_{i=1}^\ell$
$\boxed{ \left[ {\begin{array}{ccc} f_1(x_1) & \dots & f_n(x_1) \\ \dots & \dots & \dots \\ f_1(x_\ell) & \dots & f_n(x_\ell) \end{array} } \right] \xrightarrow{y} \left[ {\begin{array}{c} y_1 \\ \dots \\ y_\ell \end{array} }\right] \thinspace} \xrightarrow{\mu} a$
Test Stage
The algorithm $a$ produces answers $a(x_i^\prime)$ for new objects $x_i^\prime$
Quality Functionals
$\mathcal{L}(a, x)$ — loss function. The error magnitude of the algorithm $a \in A$ on the object $x \in X$
Loss Functions for Classification Tasks:
- $\mathcal{L}(a, x) = [a(x)\neq y(x)]$ — indicator of error
- Cross entropy is distance between two vectors of probabilities
Loss Functions for Regression Tasks:
- $\mathcal{L}(a, x) = |a(x) - y(x)|$ — absolute error value
- $\mathcal{L}(a, x) = (a(x) - y(x))^2$ — quadratic error
Empirical risk — functional quality of the algorithm $a$ on $X^\ell$:
$Q(a, X^\ell) = \frac{1}{\ell} \sum\limits_{i=1}^\ell \mathcal{L}(a, x_i)$
Reducing the Learning Task to an Optimization Task
Method of minimizing empirical risk
$\mu(X^\ell) = \arg\min\limits_{a \in A} Q(a, X^\ell)$
Example: least squares method
$Y = \mathbb{R}, \mathcal{L}$ is quadratic:
$$\mu(X^\ell) = \arg\min\limits_{\theta} \sum\limits_{i=1}^{\ell} (g(x_i, \theta) - y_i)^2$$Generalization Ability Problem
- Will we find the "law of nature" or will we overfit, i.e., adjust the function $g(x_i, \theta)$ to the given points?
- Will $a = \mu(X^\ell)$ approximate the function $y$ over the entire $X$?
- Will $Q(a, X^k)$ be small enough on new data — the test set $X^k = (x_i^\prime, y_i^\prime)_{i=1}^k$, $y_i^\prime = y(x_i)$?
Simple Example of Overfitting
Dependency $y(x) = \frac{1}{1+25x^2}$ on the interval $x \in \left[-2, 2\right]$
Feature description $x \to (1, x, x^2, \dots, x^n)$
Polynomial regression model:
$a(x, \theta) = \theta_0 + \theta_1 x + \dots + \theta_n x^n$ — a polynomial of degree $n$
Training using the least squares method:
$Q(\theta, X^\ell) = \sum\limits_{i=1}^\ell (\theta_0 + \theta_1 x_i + \dots + \theta_n x_i^n - y_i)^2 \to \min\limits_{\theta_0,\dots,\theta_n}$
Training sample: $X^\ell = \{x_i = 4\frac{i-1}{\ell-1} - 2 | i = 1, \dots, \ell \}$
Test sample: $X^k = \{x_i = 4\frac{i-0.5}{\ell-1} - 2 | i = 1, \dots, \ell-1 \}$
What happens to $Q(\theta, X^\ell)$ and $Q(\theta, X^k)$ as $n$ increases?
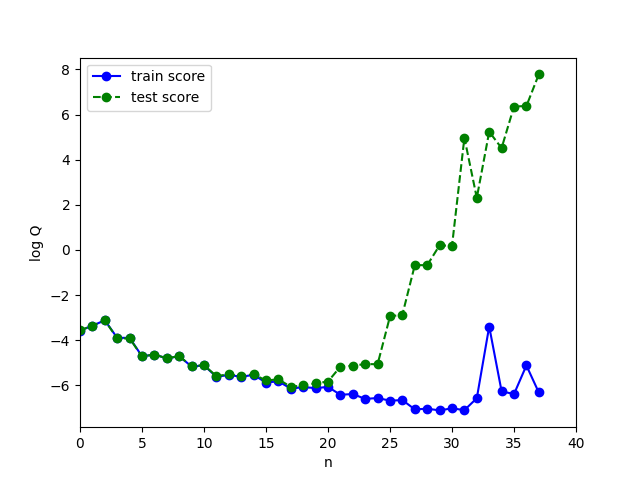
Overfitting — one of the main problems in machine learning
When test_score >> train_score
- What causes overfitting?
- Excessive complexity of the parameter space $\Theta$, extra degrees of freedom in the model $g(x, \theta)$ are "spent" on overly precise fit to the training sample
- Overfitting always occurs when there is optimization of parameters over a finite (inherently incomplete) sample
- How to detect overfitting?
- Empirically, by splitting the sample into train and test
- It's impossible to completely get rid of it. How to minimize?
- Minimize the error on validation (Hold Out, Leave One Out, Cross Validation), but with care!
- Put restrictions on $\theta$ (i.e. regularization)
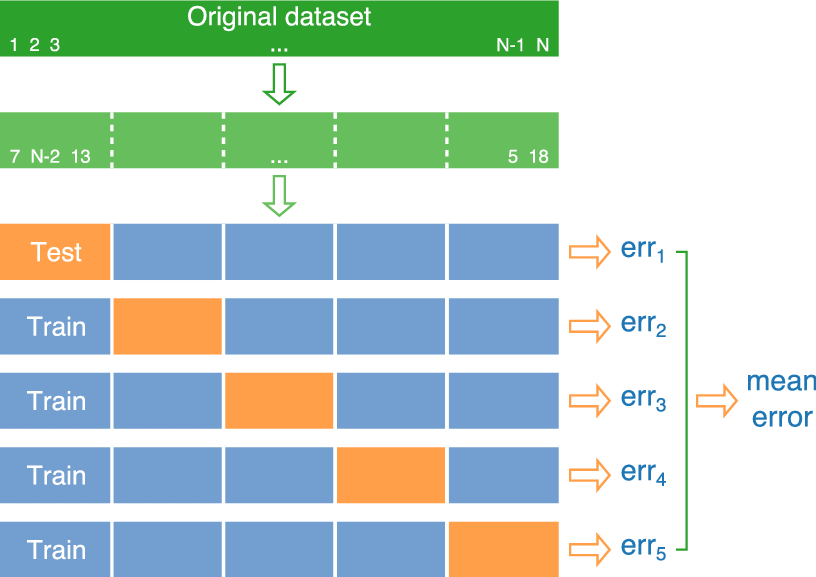
Empirical Estimates of Generalization Ability
- Empirical risk on the test data (Hold Out):
- $HO(\mu, X^\ell, X^k) = Q(\mu(X^\ell), X^k) \to \min$
- Leave One Out control, $L = \ell + 1$:
- $LOO(\mu, X^\ell) = \frac1L \sum\limits_{i=1}^L \mathcal{L}(\mu(X^\ell\backslash \{x_i\}), x_i) \to \min$
- Cross Validation, $L = \ell + k, X^L = X^\ell_n \cup X^k_n$:
- $CV(\mu, X^L) = \frac1{|N|} \sum\limits_{n \in N} {Q}(\mu(X^\ell_n), X^k_n) \to \min$
Significant Events in Machine Learning
1997: IBM Deep Blue defeats world chess champion Garry Kasparov
- 480 chess CPUs
- search using alpha-beta pruning modification
- two debut books
2004: self-driving cars competition — DARPA Grand Challenge
- prize fund of $1 million
- in the first race, the winner covered only 11.8 out of 230 km
2006: Google Translate launched
- initially statistical machine translation
- mobile app appeared in 2010
2011: 40 years of DARPA CALO (Cognitive Assistant that Learns and Organizes) development
- Apple's Siri voice assistant launched
- IBM Watson won the TV game "Jeopardy!"
2011-2015: ImageNet — error rate reduced from 25% to 3.5% versus 5% in humans
2015: Creation of the open company OpenAI by Elon Musk and Sam Altman, pledged to invest $1 billion
2016: Google DeepMind beat the world champion of the game Go
2018: At the Christie's auction, a painting, formally drawn by AI, sold for $432,500
2020: AlphaFold 2 predicts the structure of proteins with over 90% accuracy for about two-thirds of the proteins in the dataset
2021: DALL-E appears — an AI system developed by OpenAI that can generate images from textual descriptions, which has potential applications in creative industries
2022: ChatGPT (Generative Pre-trained Transformer) developed by OpenAI — the fastest-growing consumer software application in history
2024: AI gets en-Nobel-ed: John Hopfield and Geoffrey Hinton receive the Nobel Prize in Physics, David Baker, Demis Hassabis and John Jumper receive the Nobel Prize in Chemistry
Thank you for your attention!